
The reinforcement learning problem is meant to be a straightforward framing of the problem of learning from interaction to achieve a goal. The learner and decision-maker is called the agent. The thing it interacts with, comprising everything outside the agent, is called the environment.
These interact continually, the agent selecting actions and the environment responding to those actions and presenting new situations to the agent. The environment also gives rise to rewards, special numerical values that the agent tries to maximize over time. A complete specification of an environment defines a task, one instance of the reinforcement learning problem
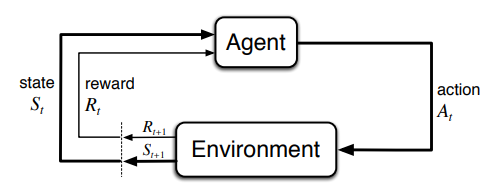
More specifically, the agent and environment interact at each of a sequence of discrete time steps, t = 0, 1, 2, 3, . . .. 2 At each time step t, the agent receives some representation of the environment’s state, St ∈ S, where S is the set of possible states, and on that basis selects an action, At ∈ A(St), where A(St) is the set of actions available in state St . One time step later, in part as a consequence of its action, the agent receives a numerical reward, Rt+1 ∈ R ⊂ R, and finds itself in a new state, St+1.