
An abstract data type (or ADT) is a programmer-defined data type that specifies a set of data values and a collection of well-defined operations that can be performed on those values. Abstract data types are defined independent of their implementation, allowing us to focus on the use of the new data type instead of how it’s implemented. This separation is typically enforced by requiring interaction with the abstract data type through an interface or defined set of operations. This is known as information hiding. By hiding the implementation details and requiring ADTs to be accessed through an interface, we can work with an abstraction and focus on what functionality the ADT provides instead of how that functionality is implemented
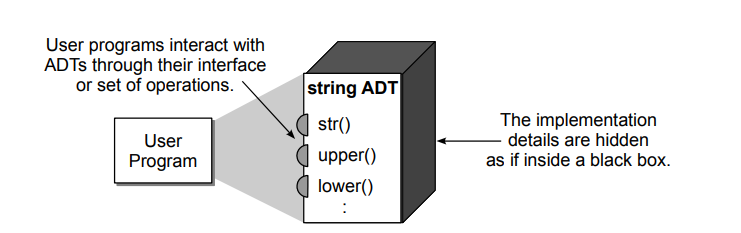
Abstract data types can be viewed like black boxes as illustrated in given below Figure. User programs interact with instances of the ADT by invoking one of the several operations defined by its interface. The set of operations can be grouped into four categories:
- Constructors: Create and initialize new instances of the ADT.
- Accessors: Return data contained in an instance without modifying it
- Mutators: Modify the contents of an ADT instance
- Iterators: Process individual data components sequentially.
Advantages of Abstract Data Types
- We can focus on solving the problem at hand instead of getting bogged down in the implementation details. For example, suppose we need to extract a collection of values from a file on disk and store them for later use in our program. If we focus on the implementation details, then we have to worry about what type of storage structure to use, how it should be used, and whether it is the most efficient choice.
- We can reduce logical errors that can occur from accidental misuse of storage structures and data types by preventing direct access to the implementation. If we used a list to store the collection of values in the previous example, there is the opportunity to accidentally modify its contents in a part of our code where it was not intended. This type of logical error can be difficult to track down. By using ADTs and requiring access via the interface, we have fewer access points to debug
- The implementation of the abstract data type can be changed without having to modify the program code that uses the ADT. There are many times when we discover the initial implementation of an ADT is not the most efficient or we need the data organized in a different way. Suppose our initial approach to the previous problem of storing a collection of values is to simply append new values to the end of the list. What happens if we later decide the items should be arranged in a different order than simply appending them to the end? If we are accessing the list directly, then we will have to modify our code at every point where values are added and make sure they are not rearranged in other places. By requiring access via the interface, we can easily “swap out” the black box with a new implementation with no impact on code segments that use the ADT.