
A Nondeterministic Finite Automaton (NFA) is a theoretical model in automata theory and formal language theory. It is a finite state machine that operates on an input string of symbols and can be in multiple states at once, making it “nondeterministic.” NFAs are commonly used to recognize and accept regular languages.
In mathematical terms, a Nondeterministic Finite Automaton (NFA) is formally defined as a 5-tuple (Q, Σ, δ, q0, F), where:
- Q: A finite set of states, where each state represents a particular configuration or condition of the automaton.
- Σ: A finite alphabet of input symbols, which is the set of all possible symbols that the automaton can read as input.
- δ: The transition function, which maps a state in Q and an input symbol in Σ to a set of states in Q. Formally, δ: Q × Σ → 2^Q, where 2^Q represents the power set of Q (the set of all subsets of Q).
- q0: The initial state, which is an element of the set Q. It specifies where the automaton begins its operation.
- F: A set of accepting states, which is a subset of Q. The automaton accepts an input string if it reaches any state in the set F after processing the entire input string.
The key feature that distinguishes an NFA from a Deterministic Finite Automaton (DFA) is the nondeterministic nature of the transition function δ. In a DFA, δ is a single-valued function (it maps each state and input symbol to exactly one state), whereas in an NFA, δ can map to multiple states, allowing the automaton to have multiple possible transitions for the same input symbol and current state.
To accept an input string, the NFA explores all possible paths through its states based on the nondeterministic choices defined by δ. If there exists at least one path that leads to an accepting state, the NFA accepts the input string. This nondeterministic behavior provides NFA with greater expressive power, making it suitable for certain types of pattern recognition and parsing tasks in computer science and automata theory.
Here are the key components and characteristics of an NFA:
- States (Q): An NFA consists of a finite set of states, denoted as Q. Each state represents a possible configuration the automaton can be in while processing an input string.
- Alphabet (Σ): The input alphabet is a finite set of symbols, denoted as Σ. These symbols are the characters from which the input strings are constructed.
- Transition Function (δ): The transition function, δ, maps the current state and an input symbol to a set of possible next states. In mathematical notation, δ: Q × Σ → 2^Q, where 2^Q represents the power set of Q. This means that for a given state q and input symbol a, δ(q, a) is a subset of Q, indicating multiple possible transitions.
- Initial State (q0): There is one designated initial state, denoted as q0, from which the processing of the input string begins.
- Accepting States (F): A subset of states from Q is marked as accepting states, denoted as F. When the NFA reaches any state in the set F after processing the entire input string, it accepts the input as part of the recognized language.
- Empty or Epsilon Transitions (ε): In addition to transitions based on input symbols, NFAs can have ε-transitions, which allow the automaton to move from one state to another without consuming any input symbol. These transitions are denoted as ε.
- Language Recognition: An NFA recognizes a language L if, for any input string w in the language L, there exists at least one sequence of states (q0, q1, q2, …, qn) and ε-transitions (if any) such that:
- q0 is the initial state.
- qn is an accepting state (q_n ∈ F).
- For each i from 0 to n-1, there exists an input symbol a_i such that q_(i+1) ∈ δ(q_i, a_i).
This means that the NFA can explore multiple possible paths through its states and transitions, including ε-transitions, to determine if an input string belongs to the recognized language.
- Non-Determinism: The non-deterministic aspect of NFAs arises from the fact that for a given state and input symbol, there can be multiple possible next states, as represented by the power set 2^Q in the transition function δ.
NFAs are formally defined mathematical models that play a fundamental role in the theory of computation. They are particularly useful for recognizing regular languages, which are a subset of formal languages defined by regular expressions. The ability to represent non-determinism makes NFAs a valuable tool in the study of formal languages and their properties.
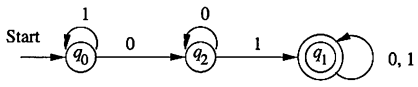
An NFA accepting all strings that end in 01
To design a nondeterministic finite automaton (NFA) that accepts all strings ending in “01,” you can follow these steps. The NFA will have states to keep track of the different possible patterns in the input string, particularly focusing on the last two characters.
- Define the set of states (Q):
- Q = {q0, q1, q2}
- Specify the input alphabet (Σ):
- Σ = {0, 1}
- Design the transition function (δ):
- For state q0:
- δ(q0, 0) = {q0} (stay in q0 for 0)
- δ(q0, 1) = {q0, q1} (move to q0 or q1 for 1)
- For state q1:
- δ(q1, 0) = {} (no transition for 0)
- δ(q1, 1) = {q2} (move to q2 for 1)
- For state q2:
- δ(q2, 0) = {} (no transition for 0)
- δ(q2, 1) = {} (no transition for 1)
- Designate the initial state (q0):
- q0 is the starting state.
- Specify the set of accepting states (F):
- F = {q2} (q2 is the accepting state, indicating that the string ends in “01”).
With this NFA:
- It starts in state q0 upon receiving the first symbol.
- If it reads a “0” in q0, it remains in q0 because the string does not yet end in “01.”
- If it reads a “1” in q0, it has two choices: it can either stay in q0 or move to q1, representing the possibility that the string has “01” as its last two characters.
- In state q1, if it encounters a “0,” it cannot continue the pattern, so there is no transition for “0,” meaning the last two characters cannot be “01.”
- However, if it reads a “1” in q1, it moves to state q2, indicating that the string ends in “01.”
- In state q2, there are no further transitions because the pattern “01” has been recognized.
This NFA will accept any input string that ends with “01” and reject all others. It leverages non-determinism to explore different possibilities in recognizing the desired pattern.
Transition table for an NFA that accepts all strings ending in 01
To create a transition table for an NFA that accepts all strings ending in “01,” you can define the states, alphabet, transitions, and accept states. Below is a simplified transition table for such an NFA:
States:
- q0: Initial state
- q1: Accept state
Alphabet:
- Σ = {0, 1} (binary alphabet)
Transitions:
| Current State | Input Symbol | Next State(s) |
|---------------|--------------|---------------|
| q0 | 0 | q0, q1 |
| q0 | 1 | - |
| q1 | 0 | - |
| q1 | 1 | - |
In this transition table:
- The NFA starts in state
q0. - When it reads a
0, it can stay inq0or transition toq1. This represents the non-deterministic choice. - If it reads a
1in stateq0, it cannot make any transitions. - If it reads a
0or1in stateq1, it cannot make any transitions.
The NFA accepts a string if it ends in state q1.
This NFA accepts all strings ending in “01” by allowing non-deterministic choices when it encounters a 0 in the second-to-last position. If it reaches the accept state q1 at the end, it means the input string ends with “01” and is accepted by the NFA.
The Extended Transition Function in NFA
Extended Transition Function (δ*) in NFAs:
The Extended Transition Function, denoted as δ* (delta star), is a crucial concept in the theory of NFAs. It helps us understand how an NFA processes an input string and keeps track of all the possible states that the NFA can be in after reading that input.
Here’s a more detailed explanation:
1. Purpose:
- The primary purpose of δ* is to describe the behavior of an NFA as it reads an input string.
- It takes into account the non-deterministic nature of NFAs, where multiple transitions can be possible from a single state for the same input symbol.
2. Definition:
- δ* is a function that maps a state and an input string to a set of possible states.
- Formally, for a given NFA with states Q, input alphabet Σ, transition function δ, and initial state q0, δ* is defined as follows: δ* (q, w) = {p | p ∈ Q and there exists a computation path from q0 to p by processing input string w}.
3. Recursive Computation:
- δ* is computed recursively. It considers the transitions the NFA can make for the first symbol of the input string and then recursively computes the transitions for the remaining part of the string.
- It takes into account ε-transitions, which are transitions that don’t consume any input (empty transitions).
4. Set of Possible States:
- The result of δ* is a set of states. This set represents all the possible states the NFA can be in after processing the input string.
- Multiple states may be included due to non-deterministic choices and ε-transitions.
5. Acceptance Determination:
- If any of the states in the resulting set of δ*(q, w) are accept states, then the input string is considered accepted by the NFA.
- In other words, the NFA accepts the input string if there exists at least one path through which it reaches an accept state after processing the entire string.
6. Practical Use:
- δ* is a fundamental concept used in algorithms for determining whether a given string is accepted by an NFA.
- It is also used in the construction of subsets of states when converting an NFA into an equivalent Deterministic Finite Automaton (DFA).
In another way, the Extended Transition Function δ* is a powerful tool for understanding the behavior of Non-Deterministic Finite Automata, allowing us to explore all possible outcomes when processing input strings and determining whether they are accepted by the NFA. It plays a crucial role in both theoretical and practical aspects of automata theory and formal language recognition.
Example of Nondeterministic Finite Automata ( NFA ):
NFA Description:
Suppose we have the following NFA with three states and an input alphabet {0, 1}:
- States: q0, q1, q2
- Input Alphabet: {0, 1}
- Transitions:
- δ(q0, 0) = {q0, q1}
- δ(q0, 1) = {q0}
- δ(q1, 0) = {q2}
- δ(q2, 1) = {q2}
- Initial State: q0
- Accept State: q2
Input String: 1001
Now, let’s compute the Extended Transition Function (δ*) for this NFA with the input string “1001.”
Step 1: Initial State
- We start in the initial state, q0.
Step 2: Processing the Input String
- We read the input string “1001” from left to right, updating our set of possible states at each step.
- δ*(q0, “1”) = {q0, q1} (We can transition from q0 to q0 or q1 on input “1.”)
- δ*(q0, “10”) = {q2} (We go from {q0, q1} to q2 on input “0.”)
- δ*(q2, “01”) = {q2} (We stay in q2 on input “01.”)
- δ*(q2, “”) = {q2} (We don’t make any transitions since the input string is empty.)
Step 3: Final State Check
- We check if there are any accept states (in this case, q2) in the set of possible states obtained after processing the entire input string.
- In this case, δ*(q0, “1001”) contains q2, which is an accept state.
Conclusion:
- Since there exists a path through which the NFA reaches an accept state (q2) after processing the input string “1001,” we conclude that the input string is accepted by the NFA.
In this example, we used the Extended Transition Function (δ*) to track all possible states as the NFA processes the input string, allowing us to determine whether the string is accepted by the NFA.
The Language of an NFA
The “language” of a Non-Deterministic Finite Automaton (NFA) refers to the set of all possible strings that the NFA can accept or recognize. In other words, it is the collection of all input strings for which the NFA can reach an accept state when processing those strings.
Here’s how to formally define the language of an NFA:
- Language Recognized by an NFA (L(N)):
- The language recognized by an NFA, denoted as L(N), is the set of all strings over its input alphabet (Σ) for which there exists at least one computation path through the NFA that leads to an accept state. Mathematically, it can be defined as:
L(N) = {w | δ*(q0, w) contains at least one accept state}
Where:
wis an input string.δ*is the Extended Transition Function, which tracks all possible states after processing the input stringw.q0is the initial state of the NFA.
- Key Points:
- The language of an NFA represents all the strings that the NFA can accept or recognize.
- The language can include finite sets of strings (regular languages) or infinite sets of strings, depending on the NFA’s design.
- If a string is in L(N), it means that there is at least one way to navigate the NFA such that the string is accepted.
- Comparison with Regular Languages:
- If the language recognized by an NFA is a regular language, it means that the NFA can be converted into an equivalent Deterministic Finite Automaton (DFA) to recognize the same language.
In another way, the language of an NFA is the set of all strings for which there exists at least one path through the NFA leading to an accept state. Understanding the language recognized by an NFA is fundamental in formal language theory and automata theory. It helps determine which sets of strings an NFA can process and accept.
Real-life example of NFA
A real-life example of an NFA (Non-Deterministic Finite Automaton) can be found in the context of recognizing keywords in a programming language. Consider a simplified scenario where we want to identify specific keywords in a programming code.
Problem:
Suppose you are building a code editor or a syntax highlighter for a programming language. You need to identify keywords like “if,” “else,” “while,” and “for” in the code to apply special formatting or coloring.
Solution using an NFA:
- Define the NFA States:
- Create states in the NFA corresponding to each keyword: q_if, q_else, q_while, q_for, etc.
- Include additional states for non-keyword code parts, such as q_code.
- Input Alphabet:
- The input alphabet consists of characters from the code.
- Transitions:
- Define transitions based on the characters in the code.
- For each keyword state, set up transitions such that when certain characters are encountered (e.g., “i” followed by “f” for “if”), the NFA moves to the respective keyword state.
- Accept States:
- Set the keyword states (e.g., q_if, q_else) as accept states.
- When the NFA reaches an accept state, it means that it has recognized a keyword.
- Non-Deterministic Behavior:
- Allow non-deterministic behavior when common prefixes exist. For example, “if” and “else” share the same “e” character as a prefix, so the NFA should handle this ambiguity.
Example:
Let’s say we have the following NFA transitions for the keywords “if” and “else”:
- δ(q_start, ‘i’) = q_i
- δ(q_i, ‘f’) = q_if (Accept state for “if”)
- δ(q_i, ‘e’) = q_ie (Continuing for potential “else” keyword)
- δ(q_ie, ‘l’) = q_els (Continuing for potential “else” keyword)
- δ(q_els, ‘s’) = q_else (Accept state for “else”)
Usage:
When processing code, the NFA reads characters one by one. As it encounters characters, it transitions through its states. When it reaches an accept state, it recognizes the corresponding keyword. This information can then be used for syntax highlighting or other code analysis tasks.
This real-life example demonstrates how an NFA can be used to recognize keywords in a programming language, showing its practical application in software development tools like code editors and syntax highlighters.
Equivalence of Deterministic and Nondeterministic Finite Automata
Equivalence Theorem:
The Equivalence Theorem states that for any regular language, there exists both a DFA and an NFA that can recognize it. In other words, DFAs and NFAs are equivalent in their computational power. This theorem is a fundamental result in automata theory and is formally expressed as follows:
For every regular language L, there exists:
- A Deterministic Finite Automaton (DFA) M such that L(M) = L.
- A Non-Deterministic Finite Automaton (NFA) N such that L(N) = L.
Understanding the Equivalence:
- DFA to NFA (NFA Simulation):
- Given a DFA M = (Q, Σ, δ, q0, F), we can construct an equivalent NFA N = (Q, Σ, Δ, q0, F), where Δ is the transition function.
- The key idea is to simulate non-determinism by allowing multiple transitions for the same input symbol from a state in the NFA.
- Formally, Δ(q, a) = {p | p = δ(q, a) for the DFA M}.
- This simulation of non-determinism in the NFA does not increase its computational power; it remains equivalent to the DFA.
- NFA to DFA (DFA Subset Construction):
- Given an NFA N = (Q, Σ, δ, q0, F), we can construct an equivalent DFA D = (P, Σ, δ’, q0′, F’), where P is the power set of Q, and δ’ is the transition function.
- The key idea is to represent the states of the DFA as subsets of states of the NFA.
- The transition function δ’ is defined such that δ'(S, a) is the set of states reachable in NFA N by starting from any state in the subset S and taking input symbol a.
- The start state q0′ is the set containing the start state q0 of N.
- The set of accept states F’ includes subsets that contain at least one accept state from F.
- The DFA D is deterministic and recognizes the same language as the NFA N.
Practical Implications:
- While both DFA and NFA are theoretically equivalent, practical considerations often determine which one to use in specific applications.
- DFAs are often preferred for implementation due to their deterministic behavior, which simplifies processing and minimizes memory requirements.
- NFAs, on the other hand, provide a more compact representation for certain languages and are commonly used in regular expression matching engines.
In summary, the Equivalence Theorem establishes the mathematical equivalence between DFA and NFA in recognizing regular languages, demonstrating their interchangeability in formal language theory while considering practical trade-offs in implementation.
Theorem 1: If D = (Qp,2, 4p, {qo}, Fp) is the DFA constructed from NFA N = (Qn, 2, 6n, 40, Fw) by the subset construction, then L(D) = L(N).
To prove the theorem that states “If D = (Qp, Σ, δp, {q0}, Fp) is the DFA constructed from NFA N = (Qn, Σ, δn, q0, Fw) by the subset construction, then L(D) = L(N),” we need to demonstrate that the languages recognized by the DFA D and the NFA N are indeed equivalent, meaning they recognize the same set of strings.
Here’s a step-by-step proof of this theorem:
Assumption:
Let D be the DFA constructed from NFA N using the subset construction method.
Proof:
Step 1: Language Recognized by NFA N (L(N)):
- Recall that the language recognized by an NFA N is defined as L(N) = {w | N can accept string w by transitioning from the initial state q0 to an accept state in zero or more steps}.
- Therefore, L(N) represents the set of strings that N can accept.
Step 2: Language Recognized by DFA D (L(D)):
- The language recognized by a DFA D is defined as L(D) = {w | D can accept string w by transitioning from the initial state q0 to an accept state in one step}.
- This means that L(D) represents the set of strings that D can accept.
Step 3: Proving L(D) ⊆ L(N) (Subset Inclusion):
- We need to show that every string accepted by D (L(D)) is also accepted by N (L(N)).
- Consider an arbitrary string w ∈ L(D). This means that D can accept w in one step from the initial state q0 to an accept state.
- Since D is constructed from N using the subset construction, the behavior of D simulates the behavior of N.
- Therefore, there exists a corresponding computation in NFA N for string w, starting from the initial state q0 of NFA N, that leads to an accept state.
- Thus, we have shown that every string accepted by D is also accepted by N.
Step 4: Proving L(N) ⊆ L(D) (Subset Inclusion):
- We need to show that every string accepted by N (L(N)) is also accepted by D (L(D)).
- Consider an arbitrary string w ∈ L(N). This means that N can accept w by transitioning from the initial state q0 to an accept state.
- Since D is constructed to simulate N’s behavior, it can also follow the same computation path as N to accept w.
- Therefore, we have shown that every string accepted by N is also accepted by D.
Step 5: Conclusion:
- From Step 3 and Step 4, we have demonstrated that L(D) ⊆ L(N) and L(N) ⊆ L(D).
- Therefore, by the subset inclusion property, we conclude that L(D) = L(N), which means that the languages recognized by the DFA D and the NFA N are equivalent.
Conclusion:
The theorem has been proven by showing that both L(D) ⊆ L(N) and L(N) ⊆ L(D), establishing the equality L(D) = L(N). This result confirms that when you construct a DFA from an NFA using the subset construction method, the languages recognized by the two automata are indeed the same.
Theorem 2: A language L is accepted by some DFA if and only if L is accepted by some NFA.
The theorem states that a language L is accepted by some Deterministic Finite Automaton (DFA) if and only if L is accepted by some Non-Deterministic Finite Automaton (NFA). This means that a language can be recognized by a DFA if and only if it can also be recognized by an NFA. Let’s prove this theorem.
Proof:
Part 1: If L is accepted by some DFA, then L is accepted by some NFA.
Let’s start with the first part of the theorem, which asserts that if a language L can be recognized by some DFA, then it can also be recognized by some NFA.
- Suppose we have a DFA D = (Q, Σ, δ, q0, F) that recognizes language L. That is, L(D) = L.
- We can create an equivalent NFA N = (Q, Σ, δ’, q0, F) from this DFA by simply using the same set of states, input alphabet, initial state, and accept states.
- The only difference is in the transition function. For each δ(q, a) in the DFA, we define δ'(q, a) = {p}, where p is the unique state in the DFA reached from q by input a. In other words, δ’ simulates the deterministic behavior of δ.
- Since L(D) = L, and we have constructed an NFA N that behaves the same way as D, it follows that L(N) = L as well.
Part 2: If L is accepted by some NFA, then L is accepted by some DFA.
Now, let’s prove the second part of the theorem, which asserts that if a language L can be recognized by some NFA, then it can also be recognized by some DFA.
- Suppose we have an NFA N = (Q, Σ, δ, q0, F) that recognizes language L. That is, L(N) = L.
- We can create an equivalent DFA D = (2^Q, Σ, δ’, {q0}, F’) from this NFA using the subset construction method.
- The set of states in the DFA D is the power set (2^Q) of the states of NFA N, where each state in the DFA represents a subset of states from the NFA.
- The transition function δ’ is defined such that for each state set S in the DFA, and each input symbol a in Σ, δ'(S, a) is the set of states that can be reached in NFA N from any state in S by input a.
- The initial state of the DFA D is the singleton set {q0}, where q0 is the initial state of NFA N.
- The set of accept states F’ in the DFA includes all state sets that contain at least one accept state from F in NFA N.
- By construction, we have ensured that L(D) = L(N) = L.
Conclusion:
Both Part 1 and Part 2 of the proof establish that if a language L can be recognized by either a DFA or an NFA, it can also be recognized by the other type of automaton. This proves the theorem: “A language L is accepted by some DFA if and only if L is accepted by some NFA.”
The Pigeonhole Principle
The Pigeonhole Principle is a fundamental concept in combinatorics and mathematics. It’s a simple and intuitive principle that deals with the distribution of objects into containers or pigeonholes. The principle states that if you have more objects than you have containers to put them in, at least one container must contain more than one object.
Here’s an explanation of the Pigeonhole Principle using everyday language:
Statement of the Pigeonhole Principle:
If you have n pigeonholes and m pigeons, where n < m, then at least one pigeonhole must contain more than one pigeon.
Explanation:
Imagine you have n pigeonholes and m pigeons, where n is the number of containers (pigeonholes), and m is the number of objects (pigeons) you want to distribute. If you have more pigeons (m) than you have pigeonholes (n), it’s inevitable that at least one pigeonhole must contain more than one pigeon.
Example 1: Birthday Paradox
A classic example of the Pigeonhole Principle is the “Birthday Paradox.” Even in a relatively small group of people, the chances of two people sharing the same birthday are surprisingly high. This is because there are 365 possible birthdays (pigeonholes), but when you have around 23 people (pigeons), the principle ensures that there’s a good chance at least one pair of people will share a birthday.
Example 2: Sock Colors
Suppose you have 5 different pairs of socks (10 socks in total) of various colors, and you want to find at least one matching pair in the dark. If you blindly pick socks one by one and put them in a drawer (5 pigeonholes), the Pigeonhole Principle guarantees that you’ll find a matching pair because you have more socks (10) than you have pigeonholes (5).
Significance:
The Pigeonhole Principle is a powerful tool in mathematics and problem-solving. It’s used in various fields, including computer science, cryptography, probability theory, and graph theory, to analyze situations where objects need to be distributed or allocated in a way that guarantees certain outcomes. It helps mathematicians and scientists solve problems by revealing constraints and limits imposed by the principle itself.
In summary, the Pigeonhole Principle is a simple yet profound concept that states if you have more objects than containers to put them in, you’ll inevitably end up with at least one container holding more than one object. This principle finds applications in various aspects of mathematics and real-world scenarios where distribution and allocation play a role.
Example to convert a DFA by NFA transition table
Non-Deterministic Finite Automaton (NFA) into a Deterministic Finite Automaton (DFA) using a transition table.
NFA Description:
Let’s consider a simple NFA with the following components:
- States: {q0, q1}
- Input Alphabet: {0, 1}
- Transitions:
- δ(q0, 0) = {q0, q1}
- δ(q0, 1) = {q0}
- δ(q1, 0) = {q1}
- δ(q1, 1) = {q0}
- Initial State: q0
- Accept States: {q1}
Step 1: Define the DFA Transition Table:
We will create a transition table for the DFA to simulate the NFA’s behavior. Each state in the DFA represents a set of states in the NFA (subset of states). The transitions between DFA states are determined by the transitions between corresponding subsets of NFA states.
| DFA State | δ(0) | δ(1) |
|---|---|---|
| {} | {} | {} |
| {q0} | {q0, q1} | {q0} |
| {q1} | {q1} | {q0} |
| {q0, q1} | {q0, q1} | {q0, q1} |
Step 2: Determine the Initial and Accept States:
- The initial state of the DFA is the ε-closure of the NFA’s initial state, which is {q0} in this case.
- Any DFA state containing an NFA accept state is an accept state in the DFA. In this case, {q1} and {q0, q1} are accept states in the DFA.
Step 3: Simplify the DFA:
- We can simplify the DFA by merging equivalent states. In this case, the DFA is already relatively simple, so no further simplification is needed.
Resulting DFA:
The resulting DFA is as follows:
- States: {{}, {q0}, {q1}, {q0, q1}}
- Input Alphabet: {0, 1}
- Transitions: As defined in the transition table above.
- Initial State: {q0}
- Accept States: {q1, q0, q1}
This DFA recognizes the same language as the original NFA. It demonstrates how to convert an NFA into a DFA using a transition table, where each state in the DFA represents a subset of states from the NFA, and transitions are determined by the NFA’s transition function and ε-closures.
Dead States and DFA’s Missing Some Transitions
A DFA, or Deterministic Finite Automaton, is a mathematical concept used in computer science and automata theory to model and analyze finite state machines. In a DFA, every state must have a transition for every possible input symbol. If a DFA has missing transitions, it can lead to issues when processing input strings.
When a DFA is missing transitions, it means that there are certain input symbols for which the DFA does not have defined state transitions. In other words, if the DFA encounters one of these missing input symbols, it will not know how to proceed, potentially causing the DFA to become stuck or fail to recognize the input string.
To ensure a DFA is complete and does not have missing transitions, you need to define transitions for every state and every possible input symbol in the alphabet. If there is an input symbol for which there is no defined transition in the DFA, it’s essential to add the missing transition to make the DFA well-defined and capable of processing all input strings correctly.
In summary, a DFA with missing transitions is not complete and may not behave as expected when processing input strings. It’s crucial to define transitions for all states and input symbols to make the DFA fully operational.
Example:
Suppose we have a DFA that recognizes binary strings where the number of “0”s is divisible by 3. This DFA has three states: q0, q1, and q2.
- q0 is the initial state and also an accepting state (meaning it represents binary strings with a number of “0”s divisible by 3).
- q1 represents binary strings with one or two “0”s.
- q2 represents binary strings with “0”s not divisible by 3.
Now, let’s define the transitions:
- From q0, if we read a “0,” we stay in q0, since the count of “0”s divisible by 3 is still divisible by 3.
- From q0, if we read a “1,” we transition to q1, as the count of “0”s becomes 1.
- From q1, if we read a “0,” we move to q2, because the count of “0”s becomes non-divisible by 3.
- From q1, if we read a “1,” we stay in q1, as the count remains 1 or 2.
- From q2, if we read a “0,” we go back to q0, as this continues to have a count divisible by 3.
- From q2, if we read a “1,” we move to q1.
Now, let’s consider an example string: “110110.”
- Start at q0 (initial state).
- Read “1” and move to q1.
- Read “1” and stay in q1.
- Read “0” and move to q2.
- Read “1” and move to q1.
- Read “0” and return to q0.
This DFA processes the string “110110” successfully, and since it ends in q0 (an accepting state), it recognizes that the input has a number of “0”s divisible by 3.
The key point to note is that for every state in this DFA, there are defined transitions for both “0” and “1” inputs. If we had missing transitions, such as not defining what happens when you encounter a “1” in state q2, the DFA could get stuck and fail to recognize certain valid inputs. Completing the transition table for all states and input symbols is crucial for ensuring that the DFA operates correctly.
Nondeterministic Finite Automata for Text Search
Non-deterministic Finite Automata (NFAs) can be a powerful tool for text search, especially when dealing with complex patterns or regular expressions. Here’s how you can use an NFA for text search:
Step 1: Define the NFA
To search for a specific pattern or regular expression in text, you first need to define an NFA that represents that pattern. The NFA consists of states and transitions between those states. Each state represents a possible position in the pattern, and transitions denote how the pattern can progress as characters are read from the text.
Step 2: Convert the Pattern to an NFA
If you’re dealing with a regular expression, you’ll need to convert it into an NFA. This process typically involves breaking down the regular expression into its constituent parts and constructing an NFA that represents the overall pattern.
Step 3: Text Search Algorithm
Now that you have an NFA representing the pattern, you can start searching through the text. The text search algorithm works as follows:
- Start at the initial state of the NFA.
- For each character in the text:
- Follow all possible transitions from the current state based on the character.
- For each transition, update the current state to the target state of the transition.
- Keep track of all possible states as you progress through the text.
- After reading the entire text, check if any of the possible states are in an accepting state. If any are, you’ve found a match for your pattern.
Step 4: Managing Non-determinism
One of the key features of an NFA is its non-determinism, which means that it can have multiple possible transitions for a given character. In the text search algorithm, you need to manage this non-determinism by exploring all possible paths through the NFA simultaneously.
This non-deterministic approach can be more flexible for complex patterns but may require more computational resources than a deterministic approach (such as a Deterministic Finite Automaton or DFA). DFAs are faster but are less flexible when dealing with certain types of patterns, like those involving “backreferences” or variable-length matches.
Step 5: Reporting Matches
As you search through the text and reach the end, you’ll know if you’ve found a match when any of the possible states are in an accepting state. When a match is found, you can report its location in the text and any associated information, depending on your application.
Step 6: Optimization
To make the process more efficient, consider using techniques like NFA simulation or Thompson’s construction to manage non-determinism. These techniques can help optimize the NFA-based text search and reduce computational overhead.
NFA-based text search is particularly useful when you need to work with patterns that can’t be easily represented by simple string matching, like regular expressions with alternation, quantifiers, or complex subpatterns. It allows you to efficiently find and extract text that matches these complex patterns in a flexible manner.
A DFA to Recognize a Set of Keywords
A Deterministic Finite Automaton (DFA) can be used to recognize a set of keywords in a given text. Here’s how you can design a DFA to achieve this:
Step 1: Define the Keywords
First, you need to define the set of keywords you want to recognize. These keywords could be reserved words in a programming language, specific terms in a document, or any set of words you want to identify.
Step 2: Design the DFA

- States: Create a state for each possible character in the alphabet. This includes the letters (A-Z, a-z), digits (0-9), and any other characters that can appear in your keywords. You should also have a special “start” state.
- Transitions: Define transitions between the states based on the characters in the alphabet. For each state, specify which state to transition to when a particular character is encountered. If a character doesn’t lead to a valid transition, you can create a special “dead” state to represent an invalid sequence of characters.
- Accepting States: Determine which states will be accepting states. These are the states where the DFA will stop when it recognizes a complete keyword. Each accepting state corresponds to one of the keywords you want to recognize.
- Start State: Designate one state as the start state. This is where the DFA begins processing the input text.
Step 3: Implement the DFA
Once you’ve designed the DFA on paper, you need to implement it in code. You can use a programming language of your choice to create the DFA. Here’s a simplified example in Python:
# Define the DFA as a dictionary of transitions
dfa = {
'start': {'i': 'q1', 'f': 'q6'},
'q1': {'f': 'q2'},
'q2': {' ': 'accept'},
'q6': {'o': 'q7'},
'q7': {'r': 'q8'},
'q8': {' ': 'accept'},
'accept': {}
}
# Define the set of keywords
keywords = {'if', 'for'}
# Function to check if a keyword is recognized
def recognize_keyword(text):
state = 'start'
i = 0
while i < len(text):
char = text[i]
if state in dfa and char in dfa[state]:
state = dfa[state][char]
i += 1
else:
break
return state == 'accept' or text[:i] in keywords
# Test the DFA
text = "if condition for loop"
words = text.split()
for word in words:
if recognize_keyword(word):
print(f"Keyword: {word}")
This code defines a simple DFA to recognize the keywords “if” and “for” in a given text. You can extend the DFA and keywords as needed for your specific application.
Step 4: Testing and Optimization
After implementing the DFA, thoroughly test it with various inputs to ensure it correctly recognizes the keywords. You can also optimize the DFA for efficiency by minimizing the number of states and transitions while maintaining its functionality.
Finite Automata With Epsilon-Transitions
Finite Automata With Epsilon-Transitions, often referred to as NFA-ε (Non-deterministic Finite Automaton with epsilon-transitions), are a variation of non-deterministic finite automata (NFAs). Epsilon (ε) is used to represent an empty or null transition, allowing the automaton to move from one state to another without consuming an input symbol. Here’s a brief explanation of NFA-ε:
Components of NFA-ε:
- States (Q): Like traditional NFAs, NFA-ε has a set of states, each representing a particular configuration or stage of the automaton.
- Alphabet (Σ): The input alphabet consists of symbols, but in NFA-ε, transitions can also be made using ε, which represents no input symbol.
- Transitions (δ): Transitions are defined as δ: Q x (Σ ∪ {ε}) → P(Q), where δ(q, a) is a set of states reachable from state q on input symbol a (or ε).
- Start State (q0): Similar to NFAs, NFA-ε has a designated start state from which the automaton begins its operation.
- Accepting States (F): A set of states from Q is marked as accepting states, and the automaton accepts input if it ends up in one of these states.
Operation of NFA-ε:
- NFA-ε extends the concept of non-determinism found in traditional NFAs. It allows the automaton to have multiple possible transitions from a given state on the same input symbol, including ε-transitions.
- When processing input, the NFA-ε can make ε-transitions, moving from one state to another without reading an input symbol. This feature adds a level of flexibility in recognizing patterns.
- The automaton explores multiple paths simultaneously, and it is considered to accept the input if there exists at least one path that leads to an accepting state. This non-deterministic aspect can make NFA-ε more expressive and efficient in certain situations, but it also makes it harder to simulate or implement.
Applications of NFA-ε:
- Regular Expression Engines: NFA-ε is used in the implementation of regular expression matching engines. Regular expressions can contain ε to indicate optional parts or zero or more repetitions.
- Compiler Design: NFA-ε plays a role in lexical analysis (lexers) and syntax analysis (parsers) phases of a compiler. It helps recognize tokens, handle ambiguities, and parse context-free grammars efficiently.
- Pattern Matching and Text Searching: NFA-ε can be used to recognize patterns in text, especially when patterns have optional parts or repetitions.
- Natural Language Processing: In NLP tasks, NFA-ε can be applied in tasks like part-of-speech tagging or recognizing named entities that have flexible boundaries.
- Validation and Parsing of Structured Data: NFA-ε can be used to validate and parse structured data formats, such as XML, HTML, or JSON, which may have optional or nested elements.
While NFA-ε offers advantages in terms of expressiveness and flexibility, it’s important to note that simulating NFA-ε in practice can be computationally more challenging than traditional DFAs (Deterministic Finite Automata) due to its non-deterministic nature. This means that when implementing NFA-ε in software, you may need to use techniques like the subset construction algorithm to convert it into an equivalent deterministic automaton.
Epsilon-Closures
Epsilon-closures are a concept used in automata theory and graph theory, particularly in the context of non-deterministic finite automata (NFA) and finite automata with epsilon-transitions (NFA-ε). An epsilon-closure, denoted as ε-closure(Q), is a set of states that can be reached from a given state or set of states using epsilon (ε) transitions, which are transitions that do not consume any input symbol. Epsilon-closures are crucial for simulating the behavior of non-deterministic automata, especially when dealing with multiple possible transitions on epsilon.
Here’s how epsilon-closures work:
Definition:
- For a given NFA or NFA-ε, ε-closure(q) represents the set of states that can be reached from state q using epsilon transitions.
- ε-closure(Q) represents the set of states that can be reached from any state in the set Q using epsilon transitions.
Computing ε-Closures:
To compute the ε-closure of a state or a set of states:
- Start with the initial state(s).
- Add these initial state(s) to the ε-closure.
- Examine all epsilon transitions from the state(s).
- For each state reachable via epsilon transition, add it to the ε-closure.
- Repeat step 3 and 4 for all newly added states until no new states can be reached.
Applications of ε-Closures:
- NFA Simulation: When simulating NFA-ε or NFA behavior, ε-closures are used to keep track of the set of states the automaton can be in at any given point during input processing.
- Subset Construction: When converting an NFA-ε to a Deterministic Finite Automaton (DFA), the ε-closures are used to determine the transitions between sets of states in the resulting DFA.
- Regular Expression Matching: In regular expression engines, ε-closures help handle constructs like “zero or more repetitions” or optional parts within regular expressions.
- Compiler Design: In lexical analysis (lexers) and syntax analysis (parsers) during the compilation of programming languages, ε-closures are used to handle ambiguous or non-deterministic grammar rules.
- Pattern Matching: When searching for patterns in text or searching for specific elements in structured data, ε-closures can be used to determine all possible matches considering optional or repetitive parts of the pattern.
Epsilon-closures are a fundamental concept in automata theory, enabling the efficient simulation of non-deterministic behavior and aiding in the conversion of non-deterministic automata into deterministic ones. They play a key role in various applications, including regular expression engines, compilers, and text processing tasks.
Extended Transitions and Languages for e-NFA’s
Extended transitions in the context of epsilon-NFAs (e-NFA) and languages refer to the way epsilon transitions (ε-transitions) affect the acceptance of strings in such non-deterministic finite automata. Epsilon transitions, also known as null transitions or empty transitions, allow the automaton to move from one state to another without consuming any input symbol. The concept of extended transitions is crucial in understanding the languages recognized by e-NFAs.
Extended Transitions (ε-Transitions):
- Definition: Extended transitions (ε-transitions) are a special type of transition in e-NFAs that occur without reading any input symbol. These transitions allow the automaton to move between states without consuming an input character.
- Representation: In graphical representations of e-NFAs, ε-transitions are typically denoted by an arrow labeled with ε or λ (the empty string) between two states.
- Effect on State Transitions: When processing input, the automaton can make ε-transitions, moving from one state to another without reading any input symbol. This allows the automaton to explore multiple paths simultaneously.
Languages Recognized by e-NFAs:
The concept of extended transitions impacts the languages recognized by e-NFAs in the following ways:
- Acceptance of Strings: In e-NFAs, a string is accepted if there exists at least one path (sequence of transitions) from the start state to an accepting state, taking into account ε-transitions. This means that the automaton can reach an accepting state by following one or more paths, and not all transitions need to be associated with actual input symbols.
- Concatenation of Languages: The presence of ε-transitions allows e-NFAs to recognize languages that are more expressive than those recognized by traditional NFAs or regular expressions. For example, e-NFAs can recognize languages where certain parts of a string are optional or can appear multiple times.
- Flexibility in Language Recognition: E-NFAs are particularly useful when dealing with languages that have patterns involving optional parts, repetitions, or variable-length sequences. The ε-transitions provide flexibility in recognizing such patterns.
- Complex Patterns: E-NFAs can be used to recognize more complex patterns, including those with variable-length sub-patterns, nested constructs, and languages that cannot be expressed using regular expressions alone.
- Ambiguities: E-NFAs can also be more ambiguous compared to traditional DFAs. An input string may have multiple possible paths through the automaton, leading to multiple valid interpretations or matches.
In another way, extended transitions (ε-transitions) in e-NFAs play a significant role in recognizing languages with flexible and complex patterns. E-NFAs are used in various applications, such as regular expression engines, lexical analysis in compilers, and text pattern matching, where patterns may involve optional or repetitive parts. These automata provide greater expressiveness and flexibility in language recognition compared to traditional finite automata or regular expressions.
Eliminating e-Transitions
Eliminating epsilon transitions (ε-transitions) from a non-deterministic finite automaton (NFA) is a process that simplifies the automaton by removing transitions that do not consume input symbols. The goal is to transform the NFA into a deterministic finite automaton (DFA) or a more straightforward NFA, making it easier to analyze and simulate.
Here’s a step-by-step guide on how to eliminate ε-transitions:
Step 1: Identify ε-Closures
Before eliminating ε-transitions, you need to determine the ε-closure for each state. The ε-closure of a state, denoted ε-closure(q), is the set of states reachable from q via ε-transitions. To compute the ε-closure for each state:
- Start with the state itself.
- For each state in the ε-closure, follow all ε-transitions and add the reachable states to the ε-closure.
- Repeat the process until no new states can be reached.
Step 2: Remove ε-Transitions
Eliminate ε-transitions from the NFA by creating new transitions that represent the ε-closure of each state. Specifically:
- For each state q and its ε-closure ε-closure(q), create new transitions from q to each state in ε-closure(q) on all input symbols.
- The ε-transitions are replaced by these new transitions. The resulting NFA no longer contains ε-transitions.
Step 3: Handle States without Transitions
After removing ε-transitions, some states may have no outgoing transitions on specific input symbols. You need to handle these cases:
- For any state q with no transition on input symbol a, create a transition from q to a “dead” state (a non-accepting state). This ensures that the automaton always has a valid transition for all input symbols.
Step 4: Subset Construction (Optional)
If you want to convert the NFA into a deterministic finite automaton (DFA), you can apply the subset construction algorithm. This algorithm creates states in the DFA that correspond to sets of states in the NFA. Each state in the DFA represents a combination of states in the NFA that can be reached based on the input symbols.
Step 5: Update Accepting States (if needed)
Review the accepting states in the NFA and determine whether they should be updated based on the ε-closures and the transitions introduced in the previous steps. Accepting states may change in the process.
FINITE AUTOMATA WITH EPSILON-TRANSITIONS
Finite Automata with Epsilon-Transitions, often referred to as NFA-ε (Non-deterministic Finite Automaton with epsilon-transitions), is a variation of finite automata used in automata theory. Epsilon (ε) is a special symbol that represents an empty or null transition, allowing the automaton to move from one state to another without consuming an input symbol. NFA-ε is particularly useful for representing non-deterministic behavior and more flexible language recognition. Here’s an explanation of NFA-ε:
Components of NFA-ε:
- States (Q): Similar to traditional finite automata, NFA-ε consists of a set of states, each representing a particular configuration or stage of the automaton.
- Alphabet (Σ): The input alphabet is composed of symbols that the automaton reads as it processes the input. In addition to input symbols, NFA-ε can have ε-transitions, which are transitions that do not consume input symbols.
- Transitions (δ): Transitions are defined as δ: Q x (Σ ∪ {ε}) → P(Q), where δ(q, a) is a set of states reachable from state q on input symbol a (or ε).
- Start State (q0): NFA-ε has a designated start state from which the automaton begins its operation.
- Accepting States (F): A set of states from Q is marked as accepting states. The automaton accepts an input if it ends up in one of these accepting states.
Operation of NFA-ε:
- NFA-ε extends the concept of non-determinism found in traditional NFAs by allowing ε-transitions. This means that the automaton can have multiple possible transitions from a given state on the same input symbol, including ε-transitions.
- When processing input, the NFA-ε can make ε-transitions, moving from one state to another without reading an input symbol. This allows the automaton to explore multiple paths simultaneously.
- The automaton explores multiple paths and is considered to accept the input if there exists at least one path leading to an accepting state. This non-deterministic aspect can make NFA-ε more expressive and efficient in certain situations.
Applications of NFA-ε:
- Regular Expression Engines: NFA-ε is used in the implementation of regular expression matching engines. Regular expressions often contain constructs like “zero or more repetitions” or optional parts, which can be efficiently handled by NFA-ε.
- Compiler Design: In the field of compiler design, NFA-ε is used in lexical analysis (lexers) and syntax analysis (parsers) phases to recognize tokens, handle ambiguous grammar rules, and parse context-free grammars efficiently.
- Pattern Matching and Text Searching: NFA-ε can be used to recognize patterns in text efficiently, especially when patterns have optional parts, repetitions, or variable-length subpatterns.
- Natural Language Processing: In NLP tasks, NFA-ε is applied in part-of-speech tagging, named entity recognition, and other tasks where language constructs can be flexible.
- Validation and Parsing of Structured Data: NFA-ε can be used to validate and parse structured data formats, such as XML, HTML, and JSON, which may have optional or nested elements.
While NFA-ε provides greater expressive power and flexibility in recognizing languages compared to traditional finite automata, it is important to note that simulating NFA-ε in practice can be computationally more challenging. In some cases, it is advantageous to convert NFA-ε into an equivalent deterministic finite automaton (DFA) for more efficient language recognition.
Example in C
Here’s an example of a Non-deterministic Finite Automaton with Epsilon-Transitions (NFA-ε) implemented in C. In this example, we’ll create an NFA-ε that recognizes strings with an even number of “0”s or “1”s.
#include <stdio.h>
#include <stdbool.h>
#include <stdlib.h>
#include <string.h>
#define MAX_STATES 100
#define ALPHABET_SIZE 3 // '0', '1', and ε
// Function to compute the epsilon closure of a set of states
void epsilonClosure(int nfa[][ALPHABET_SIZE], int numStates, int currentStates[], bool visited[]) {
for (int i = 0; i < numStates; i++) {
if (visited[i] || !currentStates[i]) {
continue;
}
visited[i] = true;
currentStates[i] = 1;
for (int j = 0; j < numStates; j++) {
if (nfa[i][2] && !visited[j]) {
epsilonClosure(nfa, numStates, currentStates, visited);
}
}
}
}
// Function to simulate the NFA-ε
bool isStringAccepted(int nfa[][ALPHABET_SIZE], int numStates, char inputString[]) {
int currentStates[MAX_STATES] = {0};
bool visited[MAX_STATES] = {false};
epsilonClosure(nfa, numStates, currentStates, visited);
for (int i = 0; inputString[i]; i++) {
int nextState[MAX_STATES] = {0};
for (int j = 0; j < numStates; j++) {
if (currentStates[j]) {
for (int k = 0; k < numStates; k++) {
if (nfa[j][inputString[i] - '0'] && !visited[k]) {
epsilonClosure(nfa, numStates, nextState, visited);
}
}
}
}
memcpy(currentStates, nextState, sizeof(nextState));
}
for (int i = 0; i < numStates; i++) {
if (currentStates[i] && nfa[i][2]) {
return true;
}
}
return false;
}
int main() {
int nfa[MAX_STATES][ALPHABET_SIZE] = {
{1, 1, 1}, // State 0
{1, 0, 0}, // State 1
{1, 1, 1}, // State 2
};
int numStates = 3;
char* testStrings[] = {"00", "11", "0011", "0101010", "1101101"};
for (int i = 0; i < 5; i++) {
if (isStringAccepted(nfa, numStates, testStrings[i])) {
printf("String \"%s\" is accepted.\n", testStrings[i]);
} else {
printf("String \"%s\" is not accepted.\n", testStrings[i]);
}
}
return 0;
}
In this C code, we define an NFA-ε with states 0, 1, and 2, and transitions based on input symbols ‘0’ and ‘1’, as well as ε (epsilon). The isStringAccepted function checks if a given input string is accepted by the NFA-ε.