
Compression techniques are methods employed to reduce the size of data or files, making them more manageable for storage, transmission, and processing. These techniques are crucial in various fields, including data storage, network communication, and multimedia applications. Here are some common compression techniques:
1. Lossless Compression:
Lossless compression retains all the original data when the file is decompressed. It’s commonly used for text files, databases, and program executables.
- Run-Length Encoding (RLE): Replaces sequences of identical elements with a single value and a count of the number of occurrences.
- Huffman Coding: Assigns variable-length codes to input characters, with shorter codes for more frequent characters.
- Lempel-Ziv-Welch (LZW): Builds a dictionary of frequently occurring patterns during compression and references them during decompression.
2. Lossy Compression:
Lossy compression sacrifices some data to achieve higher compression ratios. It is often used in multimedia applications where a small loss in quality is acceptable.
- JPEG (Joint Photographic Experts Group): Commonly used for compressing images. It achieves compression by discarding certain image details.
- MP3 (MPEG Audio Layer III): Used for compressing audio files. It discards less audible parts of the audio spectrum.
- Video Compression (e.g., MPEG, H.264): Techniques like motion compensation and quantization are used to reduce redundancy in video data.
3. Dictionary-Based Compression:
These techniques use dictionaries or tables to replace repeated sequences with shorter codes.
- Lempel-Ziv Algorithms (e.g., LZ77, LZ78): Create a dictionary of phrases during compression and refer to it during decompression.
- Burrows-Wheeler Transform (BWT): Reorders characters to improve compressibility, often used as a preprocessing step.
4. Delta Compression:
Delta compression involves encoding the differences between values rather than the values themselves.
- Delta Encoding: Represents data as differences (deltas) between sequential data rather than complete files.
5. Entropy Encoding:
These techniques leverage the statistical properties of the data for compression.
- Arithmetic Coding: Maps a string of symbols to a single floating-point number in the interval [0, 1).
- Shannon-Fano Coding: Divides a set of symbols into two subsets based on their probabilities.
6. Transform Coding:
Transform coding involves transforming the data into another domain, where it is more compressible.
- Discrete Cosine Transform (DCT): Used in JPEG compression for transforming spatial information into frequency information.
- Wavelet Transform: Decomposes the signal into multiple frequency components, allowing for more localized compression.
7. Quantization:
Quantization reduces the precision of values to achieve compression.
- Scalar Quantization: Reduces the number of bits used to represent each value.
- Vector Quantization: Applies quantization to groups of values, reducing redundancy.
8. Burrows-Wheeler Transform (BWT):
BWT rearranges the characters in a string to make it more compressible.
These compression techniques are often used in combination to achieve optimal results for specific types of data. The choice between lossless and lossy compression depends on the application requirements and the acceptable level of data loss.
Compression techniques are implemented by two algorithms. There is the compression algorithm that takes an input x and generates a representation xc that requires fewer bits, and there is a reconstruction algorithm that operates on the compressed representation xc to generate the reconstruction y.
The word algorithm comes from the name of an early 9th-century Arab mathematician, Al-Khwarizmi, who wrote a treatise entitled The Compendious Book on Calculation by al-jabr and al-muqabala, in which he explored (among other things) the solution of various linear and quadratic equations via rules or an “algorithm.” This approach became known as the method of Al-Khwarizmi. The name was changed to algoritni in Latin, from which we get the word algorithm. The name of the treatise also gave us the word algebra
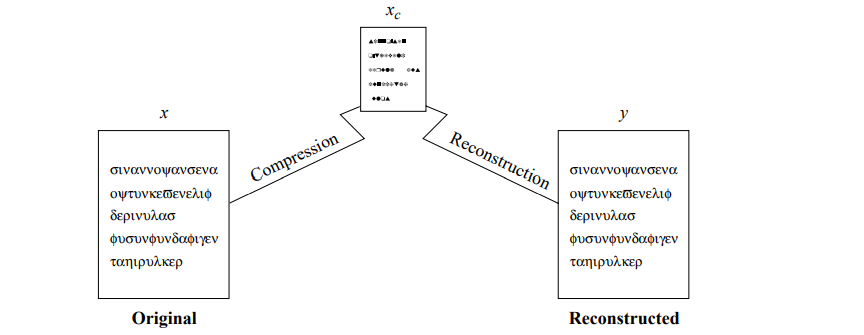
Based on the requirements of reconstruction, data compression schemes can be divided into two broad classes: lossless compression schemes, in which y is identical to x, and lossy compression schemes, which generally provide much higher compression than lossless compression but allow y to be different from x
Lossless Compression:
Lossless compression techniques, as their name implies, involve no loss of information. If data have been losslessly compressed, the original data can be recovered exactly from the compressed data. Lossless compression is generally used for applications that cannot tolerate any difference between the original and reconstructed data.
Example: Text compression
Lossy Compression:
Lossy compression techniques involve some loss of information, and data that have been compressed using lossy techniques generally cannot be recovered or reconstructed exactly. In return for accepting this distortion in the reconstruction, we can generally obtain much higher compression ratios than is possible with lossless compression.
Example: Audio Compression